Introduction à la programmation avec ISO C++
par Michel Michaud
Cette page en constante évolution contient un errata et certaines
justifications, nuances ou mises en contexte.
Un résumé (deux pages) des corrections importantes, en format Word, est disponible ici,
pour ceux qui veulent faire les corrections importantes rapidement.
Mise à jour du 9 mars 2011 : améliorations page 261 et 357.
Mise à jour du 2 mars 2011 : correction dans un commentaire page 342.
Mise à jour du 29 janvier 2011 : améliorations pages 208, 211, 222-223 et 248.
Mise à jour du 2 mars 2010 : correction page 357.
Mise à jour du 26 février 2010 : commentaire supplémentaire sur les exercices de la série O, page 350.
Mise à jour du 24 mars 2009 : commentaire sur les exercices de la série O, page 350.
Mise à jour du 20 mars 2009 : correction page 350; améliorations page 335 et 346.
Mise à jour du 19 mars 2009 : corrections pages 110 et 112.
Mise à jour du 16 mars 2009 : améliorations pages 255, 260, 350 et 402.
Mise à jour du 12 mars 2009 : commentaire général sur les commentaires (ici).
Mise à jour du 8 mars 2009 : correction page 423.
Mise à jour du 7 mars 2009 : correction page 257; améliorations pages 109 et 257.
Mise à jour du 4 mars 2009 : discussion pour page 276.
Mise à jour du 27 février 2009 : UtilXML; correction pour page 307.
UtilXML
Par ailleurs, pour mes élèves de deuxième session, qui ont acquis des
connaissances de base en XML, j'ai développé des fonctions utilitaires pour
permettre une sérialisation en XML simple. J'ai globalement appelé cet ensemble de fonctions « UtilXML ». Vous
trouverez ici (UtilXML.zip) un texte explicatif, le fichier source (et en-tête) et un
programme de démonstration. Pour lire le texte explicatif seulement (un fichier pdf), voir
ici (SerialisationAvecUtilXML.pdf).
L'errata contient des choses importantes, pouvant aider à la compréhension, puis d'autres qui sont des améliorations
ou de petits détails ayant moins d'importance, puis finalement des erreurs de présentation ou typographie. Voici d'abord
les choses importantes.
- Un problème avec la police utilisée pour l'impression finale a donné un décalage
incorrect de certains caractères, particulièrement visible avec les crochets [], mais
aussi pour l'astérisque *, les accolades {}, etc. Ces caractères sont placés trop à
gauche dans l'espace qu'ils occupent, ce qui donne l'impression que des espaces sont
en trop à certains endroits ou qu'il en manque ailleurs.
Par exemple, à la page 18, le premier exemple semble indiquer
taxe <- prix * nbArticles * TAUX_TAXE
alors qu'on devrait voir autant d'espace de chaque côté des * :
taxe <- prix * nbArticles * TAUX_TAXE
Plus dérangeant, au chapitre 10, les v[i] ressemblent souvent à v[ i] alors
que je ne veux pas laisser d'espaces dans les crochets des indices.
- Page 39 (et ailleurs) : Dans les algorithmes, les constantes nommées n'ont pas de type clairement indiqué autrement que par
la valeur montrée (qui est facultative). On devrait donc les écrire correctement selon le type supposé, si on le
connaît. Par exemple, COÛT_ASSURANCE_MÉDICAMENTS devrait être 28.0 au lieu de 28, car on suppose que c'est un
montant d'argent qui n'a pas à être entier. Pour les cas où la valeur n'est pas indiquée, il faudrait écrire le
type dans le commentaire. Ces précisions sont importantes quand il y a des expressions mixtes entre les constantes
et des variables, pour savoir si l'opération sera faite en entier ou en réel.
- Page 47 : L'avant-dernier paragraphe devrait se terminer par il faut mettre le FINSI et non pas le SINON, car il n'y
aurait pas de SINON.
- Page 55 : Il y a une différence entre la déclaration d'une constante et son utilisation (en haut de la page suivante). Il faudrait
soit TARIF_SOIR_ET_NUIT_PAR_KM (mieux) ou TARIF_SOIR_NUIT_PAR_KM partout. Je ne sais pas s'il faut corriger cette
erreur en fait ! Elle permet aux enseignants utilisant le livre de faire la correction après avoir vu ces pages
avec leurs élèves... Ceci permet alors d'expliquer un avantage d'apprendre avec des algorithmes en pseudo-code plutôt qu'avec
des vraies programmes et langages de programmation (tout le monde aura compris l'algorithme quand même).
- Page 76 : Dans le programme, à la ligne 2, il faut codeCatégorie au lieu de codeEmploi.
- Page 82 : Le dernier ÉCRIRE de la page devrait être Cet élève aura au lieu de Cet examen aura.
- Page 110 : La page devrait se terminer par ce petit paragraphe introduisant les notations octale et hexadécimale, car on en aura besoin à la section 14.3
(le paragraphe pourrait d'ailleurs être placé quelque part dans cette section) : Notons aussi que C++ permet d'écrire les nombres entiers directement en base 8
(octal, chiffres 0 à 7) et en base 16 (hexadécimal, 0 à 9 puis A à F ou en minuscules) en utilisant respectivement 0 et 0x (ou 0X)
comme préfixe. Par exemple, 28 == 034 == 0x1C.
- Page 112 : La première phrase du paragraphe qui parle des notations octale et hexadécimale des caractères devrait se terminer par :
avec respectivement \0 ou \x comme préfixe.
- Page 158 : Il manque un guillemet à la fin du premier ÉCRIRE : qui devrait être
" et ", NB_MAX_BARREAUX, " : "
- Page 159 : Il faut modifier la fin du troisième point, qui fait référence à du code inexistant. On devrait lire : On peut
aussi passer des constantes en paramètre : par exemple, le module ObtenirNbBarreaux pourrait recevoir les deux limites
en paramètres au lieu de consulter directement les constantes.
- Page 170 : Il manque la déclaration d'une variable au début de la fonction :
string cote; // Déterminée selon la note
- Page 190 : Le résultat du premier exemple devrait être 2+2 2 1 0 true false ou alors il faut que le début du code soit :
cout << 2 << ' ' << showpos << 2 << ' ' << noshowpos << 2 << ' '
- Page 202 : Au numéro 1, il y a un | au lieu d'un + dans la sixième colonne de la septième ligne (celle après les 2 2 4 6...),
il faudrait qu'elle commence par |----+ comme les autres lignes séparatrices. Par ailleurs, au numéro 3, le premier prix unitaire de
l'exemple devrait être 3.99 et non pas 3.49.
- Page 210 : Il manque une virgule dans un paragraphe au milieu de la page : ...des types par énumération dans le fichier, ce sera utile pour
le débogage.
- Page 216 : Par souci de généralité, les fonctions EnOrdreDeXYZ devrait toujours correspondre à l'opérateur < et non pas <=,
car c'est ce qu'il faut pour pouvoir les utiliser dans les fonctions de bibliothèques comme sort. C'est d'ailleurs ce qui sera fait à
la page 247. Il faudrait donc corriger le texte du bas de la page, ainsi que remplacer le <= par un < autant dans la fonction
au bas de cette page que dans celle du haut de la page 217. En général, dans le code, on pourrait tester l'équivalent de (a <= b)
en utilisant (EnOrdreDeXYZ(a, b) || MemeXYZ(a, b)) ou (!EnOrdreDeXYZ(b, a)).
- Page 217 : Dans la fonction de désérialisation du milieu de la page, il manque un point-virgule à la fin du premier getline.
- Page 240 : Dans le code du bas de la page, on appelle les fonctions SerialiserQuartDeTravail et DeserialiserQuartDeTravail (des fonctions qui
ne sont pas montrées mais qui sont assez évidentes), mais il manque le premier paramètre qui donnerait le fichier. Il faudrait donc :
SerialiserQuartDeTravail(p_es_fic, p_employé.quartsDeTravail[i]);
...
DeserialiserQuartDeTravail(p_es_fic, p_s_employé.quartsDeTravail[i]);
- Page 244 : La condition de la boucle est incorrecte. Plusieurs possibilités de correction sont possibles dont :
while (indiceRecherche != p_clients.size()
&& ! (p_clients[indiceRecherche].prenom == p_clientVoulu.prenom
&& p_clients[indiceRecherche].nom == p_clientVoulu.nom))
- Page 244 : Le dernier if de la page utilise p_es_clients alors que le paramètre n'est pas un paramètre d'entrée-sortie. Il
faudrait simplement p_clients comme dans le reste de la fonction.
- Page 250 : Il y a une déclaration const double nbMoyenPommesParJour alors que cette utilisation de const est seulement présentée
à la page 258. Il faudrait donc enlever le const.
- Page 257 : Même si le code présenté est techniquement possible, les deux fonctions devraient plutôt appeler des fonctions de sérialisation/désérialisation
qui respectent le standard appliqué jusque là pour les noms, donc SerialiserClient, SerialiserVendeur et DeserialiserClient
(et sous-entendu DeserialiserVendeur).
- Page 288 : Le texte dit que size_t est déclaré dans <stdlib>, c'est plutôt <cstdlib>.
- Page 307 : Il est indiqué que le code de la deuxième écriture est équivalent à celui de la troisième. Pour que ce soit vrai, il faudrait que les deux
écrivent la même chose. Il faut donc remplacer le "\n"; de la deuxième écriture par " !\n"; (comme on a dans la troisième).
- Page 312 : Le commentaire du résultat du OU dit que le résultat affiché serait FFCF, alors que c'est plutôt FFAF.
- Page 313 : Le commentaire du résultat du OU exclusif dit que le résultat affiché serait FFCF, alors que c'est plutôt FF09. Par
ailleurs, cet exemple est le seul qui n'a pas de << setw(4), alors il serait bon de l'ajouter.
- Page 326 : La note de bas de page portant le numéro 2 est de trop et ne correspond à aucun des appels de notes. Il faudrait renuméroter
les notes restantes dans le chapitre.
- Page 326 : Le ++date.an; devrait être ++date.année.
- Page 329 : La note de bas de page portant le numéro 7 est de trop et ne correspond à aucun des appels de notes. Il faudrait renuméroter
les notes restantes dans le chapitre.
- Page 334 : Il manque la qualification par le nom de la nom de la classe pour la fonction membre EstDansAnneeBissextile définie en dehors de la classe
au bas de la page. La définition commencerait donc par inline bool ClDate::EstDansAnneeBissextile().
- Page 347-348 : La classe ClTrace est inconsistante sur l'emploi du std::. Étant donné la simplicité de l'exemple, il serait
correct de les enlever aux deux cout.
- Page 350 : L'heure affichée dans la première ligne de l'exemple d'exécution est impossible quand on considère la deuxième ligne. Il faudrait remplacer
19:08:14 par 18:58:22.
- Page 353 : Il manque un mot dans la deuxième phrase du quatrième paragraphe : ...pour le cas simple et très fréquent des constantes
entières, on peut utiliser....
- Page 357 : Il y a deux void de trop, au bas de la page, dans la déclaration et la définition du constructeur.
- Page 381 : Le typedef est fait à l'envers (mon explication initiale utilisait #define). Il faudrait évidemment :
typedef std::string ClNomClient;
- Page 413 : Dans l'operator<<, le p_es_fic devrait être p_es_flux.
- Page 423 : Le texte indique qu'il y a un exemple de erase à la page 408. C'est plutôt à la page 406.
- Page 424 : La première ligne de la section 17.6 devrait se terminer par ...possible de fonctions membres static.
Voici quelques corrections moins importantes ou de simples améliorations :
Et voici quelques erreurs mineures de typographie ou de présentation :
- Page 28 : Le premier FIN (module) montre inutilement la parenthèse fermante en caractère gras.
- Page 49 : Le code du SINON du premier SI utilise une indentation de trois espaces seulement, il en faudrait quatre.
- Page 79 : Il manque une espace entre 5 et % dans la question 4 (... on réduit l'excédent de 5 %).
- Page 81 : Dans le livre, j'ai utilisé la convention typographique suivante : quand la dernière phrase d'un paragraphe se
termine par un bout de code montré séparément, j'ai mis un deux-points à la fin du paragraghe et le texte qui suit
le code commence par une majuscule. Par contre, quand il y a une suite de la phrase après le bout de code, je ne mets
pas de deux-points et la suite commence par une minuscule. Il y a un accroc à cette convention vers le milieu de cette
page : il faudrait Nous pourrions d'ailleurs reformuler l'exemple ainsi sans le deux-points et la suite sans
majuscule (ou encore ).
- Page 138 : Il manque les espaces avant les points d'exclamation dans les deux écritures de l'exercice 1 (la convention typographique
peut être discutable, mais c'est comme ça dans le reste du livre).
- Page 186 : Il y a une virgule inutile à la fin du commentaire du getline au bas de la page.
- Page 217-218 : (Voir explication pour la page 81) Le dernier paragraphe devrait se terminer par Par exemple, avec sans le
deux-points et la suite, au haut de la page 218 devrait commencer par une minuscule (on obtiendra un fichier...).
- Page 271 : Au bas de la page, le texte sous le N. B. devrait être décalé d'une espace pour être bien aligné.
- Page 297 : (Voir explication pour la page 81) Vers la fin de la page, il faudrait Mais on peut aussi simplement faire un typedef
sans le deux-points et la suite sans majuscule (Et par la suite, par exemple :).
- Page 300 : Il y a une ligne blanche inutile en haut de la page. Par ailleurs, le point-virgule dans le premier paragraphe devrait être une simple virgule.
- Page 303 : Dans les exemples en bas de la page, il y a un identificateur qui contient un accent (noEmployé). Bien que je crois qu'il faut mettre
les accents si notre environnement de développement le permet, j'ai choisi de ne pas en mettre dans le livre alors celui-ci devrait être enlevé.
- Page 317 : La première ligne devrait être rattachée au dernier paragraphe de la page précédente.
- Page 320 : L'espace et le deux-points de la fin du deuxième paragraphe sont inutilement dans la police utilisée pour le code seulement.
- Page 325 : (Voir explication pour la page 81) Vers le milieu de la page, il faudrait Avec la fonction MoisEnTexte suivante
sans deux-points.
- Page 328 : La deuxième ligne de la note de bas de page est mal alignée.
- Page 335 : Dans l'avant-dernier paragraphe, il manque une espace entre date.ClDate() et est invalide.
- Page 341 : Le mot static devrait être en police Courier, utilisée pour le code.
- Page 342 : (Voir explication pour la page 81) Il faudrait Par exemple, avec sans le deux-points et la suite sans majuscule (on
pourrait faire :).
- Page 343 : (Voir explication pour la page 81) Il faudrait On conviendra qu'il est plus facile de code et de lire et
Mais en supposant qu'on fasse sans les deux-points et la suite du premier sans majuscule (que l'équivalent, si la
fonction...).
- Page 349 : (Voir explication pour la page 81) Vers la fin de la page, il faudrait ...dans l'ordre inverse des déclarations (donc
des constructeurs). Le code suivant (sans deux-points).
- Page 386 : (Voir explication pour la page 81) Vers la fin de la page, il faudrait ...cette fonction pourtant simple
sans deux-points.
- Page 426 : (Voir explication pour la page 81) Vers la fin de la page, il faudrait ...un peu comme des fonctions. Par exemple
sans deux-points.
- Page 428 : Il y a une espace de trop dans le bout de code du haut de la page entre le deuxième << et le p_messageErreurPrecis.
- Page 432 : La dernière section du bas de la page (sur les numeric_limits<double>::min et max) devrait être rapportée au début de la
prochaine page, afin de ne pas couper la cellule du tableau et son texte.
- À plusieurs endroits, le livre parle de TPS ou de TVQ et utilise des taux qui sont peut-être désuets. Idéalement les taux présentés
devraient être complètement farfelus afin de ne pas donner cet aspect désuet. Par ailleurs, la TVQ est peut-être un mauvais exemple
pour les lecteurs hors Québec qui utilisent le livre... Désolé.
- Page 10 : En C++, la « mode » n'est plus de mettre les noms des constantes en
majuscules. Malgré tout, j'ai choisi de le faire dans le livre pour plusieurs
raisons. D'abord c'est classique en Java et en C, et encore fréquent même en
C++. Deuxièmement, je voulais une notation très différente des autres
identificateurs. Finalement, ça permet d'apprendre à lire des identificateurs en
majuscules et aussi des identificateurs contenant des soulignements (on en aura
aussi plus tard avec des minuscules, pour les noms de paramètres, variables
globales et données membres).
- Page 18-20 : Bien qu'il soit mentionné deux fois et que le premier exemple d'expressions l'utilise, il semble que les débutants
oublient rapidement l'existence de l'opérateur de négation (- unaire). Il faut donc y apporter une attention particulière.
- Page 23 : J'ai utilisé ce truc de notation + 0.99999 pour le plafond parce qu'il était plus facilement compréhensible pour
des débutants que l'introduction d'une pseudo-fonction genre PLAFOND(nb), mais je ne suis pas complètement
satisfait de ce choix. Par exemple, on ne peut pas écrire simplement l'équivalent de
SI nb = PLAFOND(nb) comme on pourra le faire en C++.
Par contre, le principe du plafond est vraiment utile dans certains exercices réalistes qui se
donnent bien aux débutants, alors je ne voudrais pas retarder son introduction... Dans une autre
vie, je réessayerais la notation fonctionnelle...
- Page 29 : Pourquoi le nom des types est-il en minuscules alors que les autres identificateurs sont en majuscules ? Pour
trois raisons. D'abord simplement pour rendre les règles moins triviales pour les mots clefs ! Il faut accepter
le fait que ce n'est pas toujours simple. Deuxièmement je voulais simplement nuancer l'idée des mots clefs : les
noms de type n'en seront pas toujours (en C++). Finalement, c'est plus joli ainsi, dans la section VARIABLES.
- Page 35 : Le texte indique que Par principe chaque ÉCRIRE affiche une nouvelle ligne. On devrait peut-être plutôt
dire généralement. En effet, comme on n'a pas indiqué de façon spéciale pour écrire sans changer de
ligne, on suppose qu'un commentaire pourrait indiquer que ce n'est pas le cas, si c'est important pour l'algorithme
(c'est le genre de détails qui ne devraient pas être importants pour un algorithme, et d'ailleurs on omettra l'écriture
des messages à un certain point, mais il arrive que ce soit important si on donne des exercices de certains types).
- Page 41 : La technique utilisée pour faire la trace a été choisie parce que bien explicite dans un livre, mais ce n'est pas la
méthode que j'utilise quand je fais une trace en direct devant des élèves, car elle prend beaucoup trop de place quand
il y a beaucoup de variables ou d'opérations. Normalement je mets donc simplement le nom des variables verticalement
et j'indique directement la valeur que je leur affecte (en effaçant ou barrant la valeur précédente le cas échéant).
Par exemple, après quelques étapes de la trace de la page 88, on pourrait voir :
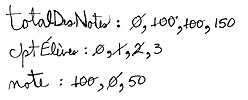
C'est beaucoup plus simple et la plupart du temps suffisant, mais ça ne permet pas de revenir en arrière pour voir la
progression aussi clairement que la méthode utilisée dans le livre. Il faut montrer l'autre manière, car les élèves
n'auront vraiment pas tendance à faire des traces si la seule possibilité est celle montrée dans le livre.
- Page 80 : Ah les boucles et demi... D'abord un aperçu du problème, pour les débutants.
Vers la fin des années 60 (1960 !),
plusieurs experts en informatique ont amené l'idée qu'il fallait une plus grande discipline afin de simplifier la
programmation des systèmes complexes. Ce mouvement a donné naissance à la programmation structurée. Plusieurs versions
ou compréhensions différentes de ce que ça signifiait ont existé parallèlement. En gros, on peut dire que ça signifiait
qu'il fallait limiter la structuration des programmes à des structures de contrôle spécifiques (séquentielle, conditionnelle
et itérative, selon diverses formes limitées proposées). Plusieurs programmeurs et experts célèbres, dont Donald E. Knuth, ont
eu de la difficulté à accepter aveuglément de se limiter à ce que certains proposaient. En fait, même si on s'entend aujourd'hui
sur la nécessité, à l'époque, de cette évolution de la façon de programmer, la plupart des programmeurs n'y pensent pas
vraiment et programment naturellement d'une façon qu'ils considèrent structurées. Il faut avoir vu les anciens programmes
remplis de « goto » pour comprendre que le temps de la programmation « non structurée » est bel et bien révolu.
Alors quel est le problème, direz-vous... Ce que selon certains académiciens (dont probablement E.W. Dijkstra, l'auteur de
l'article célèbre « Go to statement considered harmful » de 1968), une boucle devrait avoir sa sortie au début ou à la fin.
Pas au milieu. Il est difficile de dire si c'est parce que les langages de l'époque qui permettaient la programmation structurée
(Algol par exemple) n'avait pas d'instruction de boucle avec sortie dans le milieu ou si c'est un argument plus philosophique.
Les discussions rapportées par Knuth (dans « Literate Programming ») ne semblent pas tout à fait tranchées. Pour certains,
comme McConnell dans « Code Complete », il est clair qu'une boucle avec sortie au milieu est tout à fait structurée. On
peut citer aussi le cas de Ada, un langage de programmation « moderne » conçu selon des principes stricts : sa
structure de boucle ordinaire permet la sortie n'importe où... En fait, on pourrait ajouter qu'il y a aussi des discussions sur
la nécessité d'avoir un seul point de sortie ! Mais on peut dire que pour la très grande majorité, les structures de contrôle
acceptables en programmation structurée doivent avoir un seul point d'entrée et un seul point de sortie.
Personnellement j'ai adopté l'idée de la boucle générale avec (une seule) sortie n'importe où. En fait, cette idée permet de
présenter les boucles plus facilement, en insistant d'abord sur l'idée des instructions qui se répètent. Ceci rend l'apprentissage
bien plus facile pour les débutants. De plus, les boucles avec sortie au milieu arrivent plus souvent dans les programmes de débutant
que par la suite. J'ai aussi vérifié qu'une fois l'apprentissage de base terminé, disons pour des élèves de deuxième ou troisième année,
il est facile
de programmer en mettant les sorties au début ou à la fin seulement, ne serait-ce que parce que le découpage en fonction (qui est vu
après les boucles chez les débutants) permet de remplacer :
for(;;)
{
instructionsAvant1;
instructionsAvant2;
/***/
if (condition) break;
/***/
instructionsAprès1;
instructionsAprès2;
}
par quelque chose de semblable à
bool AvantEtTest()
{
instructionsAvant1;
instructionsAvant2;
return !condition;
}
while (AvantEtTest())
{
instructionsAprès1;
instructionsAprès2;
}
En fait, je ne crois pas qu'en général on puisse penser à cette façon de faire directement. On peut penser à la sortie de boucle
au milieu et découper naturellement les instructions avec une fonction, mais la logique de base reste celle d'une sortie de boucle
après et avant (donc au milieu) des instructions à répéter.
Et non, comme la plupart des experts d'ailleurs, je ne considère pas que la répétition des instructions avant
la boucle est une solution correcte (c'était une solution classique pour les débutants qui apprenaient avec Pascal). Il y a des
principes encore plus forts que la programmation structurée et la (non) répétition de code semble un de ceux-là. C'est donc
vraiment faire prendre une mauvaise habitude que de permettre la répétition. Il est intéressant de noter que Modula-3, créé par
Wirth après Pascal, comporte une boucle généralisée permettant la sortie au milieu.
Alors voilà. Pour moi (et je ne suis pas seul avec cette opinion), il n'y a aucun problème à permettre une boucle avec sortie au milieu.
C'est structuré, ça rend parfois les programmes plus simples et plus clairs, et c'est facile à faire dans la plupart des langages de programmation modernes. De plus,
elles simplifient l'apprentissage de la programmation. Si un entreprise demande à ses programmeurs de ne faire que des boucles avec sortie au début (par exemple), n'importe quel
programmeur moindrement expérimenté saura facilement comment s'adapter. En fait, au contraire, si un programmeur n'a appris
que des boucles while et do-while, il pourrait faire des programmes présentant une structure inutilement complexe lorsqu'une
boucle généralisée est permise et qu'il ne l'utilise pas.
- Page 85 : Deux philosophies s'affrontent pour le test des boucles à compteur (sans instruction directement équivalente au POUR du pseudo-code).
Celle de mettre la condition normale et celle de mettre une condition préventive. Par exemple, dans cette page, j'ai mis JUSQUE cptÉlèves >= NB_ÉLÈVES, ce qui est
préventif car le > ne devrait jamais arriver. La condition normale est donc avec un simple = en fait. Je n'utiliserai pas de condition
préventive quand on fera du C++, les boucles seront du genre for (int i= 0; i != MAX; ++i)
et non pas for (... i < MAX ...). Tout comme Andrew Koenig (je dis ça pour être en bonne compagnie,
mais d'autres personnes célèbres ne sont pas d'accord), je trouve que mettre la condition préventive ne fait que cacher les
bogues qui doivent être trouvés et corrigés. Et mettre > rend la découverte du bogue plus difficile... Tout ça pour dire
qu'à cette page, j'aurais pu mettre = au lieu du >=...
- Page 97 : Oui, le numéro 10 est « illogiquement » compliqué par le fait que le vendeur 999 peut exister, tout comme des ventes
de 0 pour les autres vendeurs. Ce n'est pas un problème réaliste, mais ça donne un algorithme intéressant !
- Page 109 : Visual C++, à partir de la version 2003, permet de mettre les accents dans les identificateurs et j'imagine qu'il n'est pas
le seul. Mes élèves utilisent donc les accents dans leurs programmes et je recommande fortement de le faire pour suivre l'idée
de base d'avoir des identificateurs clairs et précis.
- Page 146 : Le standard présenté ne couvre pas tout le livre, même s'il couvre plus que ce qui est connu à ce point. Une version plus
complète se trouve ici, mais elle doit être révisée bientôt. Inversement, on pourra trouver
ici une version plus détaillée, mais qui couvre simplement la matière des dix premiers chapitres.
- Page 174 : Certains pourraient s'objecter à cette façon de quitter les fonctions prématurément. En C++ (et dans les autres langages
semblables à C), c'est très commun et accepté par presque tout le monde, mais comme c'était impossible en Pascal, certaines
personnes pensent que ce n'est pas structuré, car une fonction « devrait avoir un seul point de sortie ». C'est vrai qu'il
ne faut pas abuser des sorties prématurées, mais elles peuvent vraiment aider à la lisibilité dans certains cas. Ici, encore une
fois, il est intéressant de noter que Modula-3, créé par Wirth après Pascal, comporte une possibilité de sortie prématurée des
fonctions. Finalement, avec le principe des exceptions, on verra qu'il y a aussi d'autres façons de quitter les fonctions
prématurément de toute façon. Si l'abus nous fait peur, notre standard de programmation pourrait limiter les possibilités
de sortie prématurée en disant qu'on peut seulement l'employer au début des fonctions, avant tout traitement important, pour
quitter la fonction à partir d'un if au premier niveau.
- Page 204 : Le livre passe sous silence, délibérément, le fait que les variables de type enum peuvent en fait contenir autre chose que les
valeurs du type. C'est le cas par exemple des variables non initialisées explicitement (une des raisons principales de l'introduction de
assert), mais on peut aussi affecter des combinaisons de valeurs (avec |) et c'est une technique souvent utilisée... Je considère
que c'est une technique trop avancée pour être présentée à ce point. Les opérations de manipulations de bits sont présentées au chapitre 14,
mais on n'y parle pas de type par énumération.
- Page 243 : Pour le paramètre donnant la valeur recherchée dans les fonctions de recherche, on aurait préféré mettre le suffixe Recherché (ou
même Désiré) plutôt que Voulu, mais ça sonne beaucoup moins bien et ça porte à confusion quand on ne met pas les accents.
Si on code avec les accents, on a donc le choix...
- Page 245 : Le code montré pour le retrait dans un vecteur non ordonné est correct dans tous les cas, y compris pour le retrait du seul
élément d'un vecteur contenant un seul élément. Bien sûr, on peut faire mieux que les deux instructions montrées pour ce cas, car
l'affectation est inutile, mais le coût du test nécessaire pour détecter ce cas particulier risque fort d'être plus coûteux au
total que l'affectation inutile (si c'est le cas). Comme notre but n'est vraiment pas l'optimisation (à ce point), il est
probablement mieux de passer sous silence toute cette discussion, comme le fait le livre, mais il faut être prêt à en parler
si quelqu'un pose une question en ce sens. (peut-être qu'une note de bas de page aurait fait l'affaire, mais j'en abuse déjà !)
Notons aussi que certaines personnes préfèrent utiliser la fonction membre erase, qui décale pourtant les éléments, même pour
les retraits dans un vecteur non ordonné, à moins qu'un problème de vitesse démontre qu'il faudrait faire mieux.
- Page 289-297 : La section sur les pointeurs et celle sur l'allocation dynamique ont été mises dans ce chapitre parce que c'est un type de
donnée et des opérations associées. Par contre, à ce point-ci dans le livre, l'emploi des pointeurs et de l'allocation
dynamique n'est pas justifié. Par conséquent, dans mon enseignement, je saute ces sections pour y revenir plus tard, au
moins après le chapitre 14, de façon à ce que ces notions un peu abstraites soient plus fraîches en mémoire des élèves.
- Page 304 : L'exercice 3c est fait pour que la solution normale ne pose pas de problème, car il y a une petite subtilité dans ce genre de problème, puisque le
+ de concaténation ne fonctionne qu'avec au moins une std::string comme opérande. Par exemple, supposons qu'on veut l'initiale
du prénom suivi d'un point, d'une espace et du nom de famille, pour le cas où le nom serait plus grand que 20 caractères. Le code
nom= prenom[0] + ". " + famille;
ne fonctionne pas, car le premier + est appliqué entre un char et une chaîne C (pas une std::string). Par contre,
subtilement, ceci fonctionne :
nom= prenom[0] + (". " + famille);
- Page 311 : La section sur les opérateurs de manipulations de bits a été mise dans ce chapitre afin de le rendre plus complet. Par contre,
il s'agit d'opérateurs qui ne seront pas utilisés dans la suite du livre. Par conséquent, dans mon enseignement, je saute cette
section si je sais que d'autres cours reviendront sur le sujet de la manipulation de bits.
- Page 350 : Les deux exercices de cette série sont, d'une certaine façon, sous-spécifiés. C'est par choix, afin que les élèves puissent considérer le design
des classes comme une activité à ne pas négliger. (j'aimerais en dire beaucoup plus, mais pas aux élèves qui liraient ce document; si vous
êtes prof, que vous utilisez mes livres et pensez donner ces exercices à faire, écrivez-moi !) Par ailleurs, le deuxième exercice profite
du fait qu'on a présenté deux classes de traitement (voir page 354) dans les pages précédentes, mais n'utilise en rien ce qui a été montré
depuis la dernière série d'exercices (fonction static et destructeur). Ça pourrait surprendre ceux qui s'attendent à des exercices
sur ces sujets, d'ailleurs l'exercice 1 nécessite un destructeur, mais n'utilise pas non plus de fonction static.
- Page 358 : Le texte donne une raison d'utiliser des push_back au lieu d'un resize. Une autre raison serait que la classe des
éléments ne contient pas de constructeur par défaut. Par ailleurs, pour des raisons d'efficacité, on pourrait normalement utiliser la
fonction reserve de std::vector, mais elle n'est pas présentée dans ce livre.
- Page 361 : Il faudrait faire remarquer que la fonction ObtenirVarietePomme pourrait être inutile, si on utilisait la classe ClMenu,
en principe développée auparavant dans les exercices de la série O.
- Page 368 : La possibilité de faire une fonction de comparaison semblable à Compare, mais static et à deux paramètres pourrait être
ajoutée. On pourrait aussi parler de faire une fonction friend et y revenir quand on en parle, dans la section 15.20.
